利用阿里云容器服务打通TensorFlow持续训练链路
第一篇:打造TensorFlow的实验环境
第二篇:轻松搭建TensorFlowServing集群
第三篇:打通TensorFlow持续训练链路
本文是该系列中的第三篇文章,将为您介绍如何利用阿里云的服务快速搭建TensorFlow从训练到服务的交付平台。
随着google开源TensorFlow的脚步越来越迅猛,机器学习已经渐渐由昔日王谢堂前燕,飞入寻常百姓家。如何把机器学习的成果,迅速转化成服务大众的产品。以TensorFlow为例,一个典型的交付流程,就是TensorFlow根据输入数据进行模型训练,待训练结束和验证确定后,模型会被发布到TensorFlowServing,就可以为大众服务了。如果能像流水线生产一辆汽车一样来实现机器学习的产品化,听起来是不是让人激动不已?
但是理想很丰满,现实很骨感,一个完整可用的机器学习生产线并不是只有TensorFlow和TensorFlowServing就够用的,如果希望这个过程更加高效和自动化,它还需要在一些基础架构层面的支持,比如:
机器学习过程中从系统到应用的监控,其中包括
a.整体计算资源特别是GPU的使用情况:使用率,内存,温度
b.每个机器学习应用的具体使用资源情况
c.机器学习过程的可视化
快速高效的问题诊断
通过集中化日志的管理控制台进行轻松的一站式问题诊断
一键式的失败恢复
a.从失败节点调度到可用节点
b.分布式存储保存计算中的checkpoint,可以随时在其它节点继续学习任务
模型的持续改进和发布
a.利用分布式存储将模型无缝迁入生产环境
b.蓝绿发布
c.模型回滚
下面我们就展示一下利用阿里云容器服务快速的搭建一套从模型学习到发布的过程,这会是个逐步迭代不断优化的方案.我们后面的文章会不断迭代优化这一方案,希望容器服务在应用交付和运维方面的经验帮助数据科学家们专注于机器学习价值本身,进而提供最大的价值。目前我们的方案运行在CPU机器上,未来待HPC与容器服务的集成完成后,这个方案非常容易迁移到HPC容器集群。
机器学习生产线的搭建
前期准备
创建阿里云容器服务,参考
创建OSS数据卷,这个具体步骤可以参考文章
创建阿里云日志服务,具体步骤可以参考
有了这些服务,我们就可以在阿里云容器服务上和机器学习愉快的玩耍了,我们使用的例子是机器学习界的Helloworld---MNIST
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:
它也包含每一张图片对应的标签,说明这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1
首先确认OSS数据卷mnist_model被创建出来了,并且要在mnist_model创建Minst_data文件夹,并下载所需的训练集与测试集数据
文件内容训练集图片-55000张训练图片,5000张验证图片训练集图片对应的数字标签测试集图片-10000张图片测试集图片对应的数字标签2.用如下的docker-compose模板在阿里云上一键部署TensorFlowLearning的环境,
version:'2'
services:
tensor:
image:/cheyang/mnist-export
command:
-"python"-"/mnist_"-"--training_iteration=${TRAIN_STEPS}"-"--export_version=${VERSION}"-"--work_dir=/mnist_export/Minst_data"-"/mnist_export/mnist_model"volumes:
-mnist_model:/mnist_exportlabels:
-_store_mnist=stdoutenvironment:
-CUDA_VISIBLE_DEVICES=-1
注:
在阿里容器服务中创建应用时,就会弹出对话框,里面需要输入的是模型版本和训练参数,我们输入的模型版本为1和训练参数为100
有了_store_mnist,就可以在阿里云的日志服务中看到整个学习过程,方便问题的分析和诊断
当学习任务完成后,可以登录到服务器上看到学习出来的模型
3.现在需要做的事情就是启动一个TensorFlowServing把学习出来的模型发布到生产环境,这里提供如下的docker-compose模板
version:'2'
services:
serving:
image:/denverdino/tensorFlow-serving
command:
-"/serving/bazel-bin/tensorFlow_serving/model_servers/tensorFlow_model_server"-"--enable_batching"-"--port=9000"-"--model_name=mnist"-"--model_base_path=/mnist_model"volumes:
-mnist_model:/mnist_modellabels:
-_store_serving=stdoutports:
-"9000:9000"environment:
-CUDA_VISIBLE_DEVICES=-1
注:
4.可以在日志服务中直接查看一下TensorFlowServing的日志,发现版本1的模型已经加载到了serving中了
同时需要查看一下该服务的point,在这里TensorFlowServing的point是10.24.2.11:9000。当然我们还可以将服务发布到SLB上,这在文章利用Docker和阿里云容器服务轻松搭建TensorFlowServing集群中已经有了比较详细的描述,就不在本文中赘述了。
5.为了验证TensorFlowServing,需要部署一个测试的客户端,下面是测试客户端的docker-compose模板
version:'2'
services:
tensor:
image:/denverdino/tensorFlow-serving
command:
-"/serving/bazel-bin/tensorFlow_serving/example/mnist_client"-"--num_tests=${NUM_TESTS}"-"--server=${SERVER}"-"--concurrency=${CONCURRENCY}"
创建应用的时候就会需要输入测试次数NUM_TESTS,TensorFlowServing的pointSERVER,以及并发访问量CONCURRENCY
当应用创建完成后,可以看到运行结果如下,我们发现这时候的错误率是13.5
serving-client_tensor_1|2016-10-11T12:46:59.314358735ZD101112:46:59.3142175225ev_:101]Usingpollingengine:poll
serving-client_tensor_1|2016-10-11T12:47:03.324604352Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T12:47:03.324652816Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T12:47:03.324658399Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T12:47:03.324661869Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T12:47:04.326217612Z.
serving-client_tensor_1|2016-10-11T12:47:04.326256766ZInferenceerrorrate:13.5%
serving-client_tensor_1|2016-10-11T12:47:04.326549709ZE101112:47:04.32648453369chttp2_:1810]close_transport:{"created":"@1476190024.326451541","description":"FDshutdown","file":"src/core/lib/iomgr/ev_poll_","file_line":427}
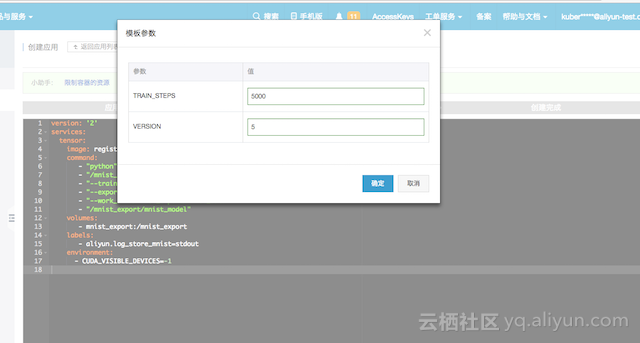
6.为了提升识别效果,就需要调整参数重新运行一次TensorFlowLearning应用重新发起一次训练.可以直接在容器云服务的页面点击变更配置
这时会弹出对话框,里面需要输入的是模型版本和训练参数,我们输入的模型版本为2和训练参数为2000
当学习完成后,再次查看NAS服务器,发现多了一个新的模型
而这个时候查看TensorFlowServing的日志,就会发现模型已经更新到了版本2
此时重新运行测试客户端,可以发现错误率降低到8.5%,看到新的模型在识别能力上有一定的提升
serving-client_tensor_1|2016-10-11T16:54:34.926822231ZD101116:54:34.9267312045ev_:101]Usingpollingengine:poll
serving-client_tensor_1|2016-10-11T16:54:37.984891512Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T16:54:37.984925589Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T16:54:37.984930097Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T16:54:37.984933659Z('Extracting','/tmp/')
serving-client_tensor_1|2016-10-11T16:54:39.038214498Z.
serving-client_tensor_1|2016-10-11T16:54:39.038254350ZInferenceerrorrate:8.5%
serving-client_tensor_1|2016-10-11T16:54:39.038533016ZE101116:54:39.03848136168chttp2_:1810]close_transport:{"created":"@1476204879.038447737","description":"FDshutdown","file":"src/core/lib/iomgr/ev_poll_","file_line":427}
PS:整个工作流程中,我们并没有SSH登录到任何主机上,完全是在容器服务管理平台上操作的。
总结
这仅仅是一个开始,TensorFlow和TensorFlowServing也仅仅是一个描述阿里云容器服务对于高性能计算支持的一个例子,在本节中,我们通过OSS实现了从把学习出的模型交付到对外服务,并且实现了模型的迭代,同时又利用日志服务一站式查看容器工作日志。这种方式只是实现了最基本的持续学习持续改善的概念,在生产环境还需要更加严格的验证和发布流程,我们将在未来文章中,介绍我们的方法和实践。
阿里云容器服务还会和高性能计算(HPC)团队一起配合,之后在阿里云上提供结合GPU加速和Docker集群管理的机器学习解决方案,在云端提升机器学习的效能。
想了解更多容器服务内容,请访问