终结扩散模型:OpenAI开源新模型代码,一步成图,1秒18张
机器之心报道
机器之心编辑部
与高调推出ChatGPT、GPT-4不同,这次OpenAI在上个月偷偷上传了一篇论文《ConsistencyModels》,也不能说是偷偷,只是这次没有媒体大张旗鼓的报道,就显得这项研究有些低调。论文内容主要是关于图像生成领域的。
作者阵容也非常强大,有本科毕业于清华大学数理基础科学班、目前在OpenAI担任研究员的宋飏。宋飏将于2024年1月加入加州理工学院电子系(ElectricalEngineering)和计算数学科学系(ComputingandMathematicalSciences)担任助理教授。此外还包括OpenAI联合创始人、首席科学家IlyaSutskever。
前面我们已经提到,OpenAI的这项研究主要是图像生成方面的,大家或多或少的都听过这项技术,例如最近热门的Midjourney和StableDiffusion,它们大都采用扩散模型,由于其生成的图片效果惊艳,很多人都将其视为最好的工具。但扩散模型依赖于迭代生成过程,这导致此类方法采样速度缓慢,进而限制了它们在实时应用中的潜力。
OpenAI的这项研究就是为了克服这个限制,提出了ConsistencyModels,这是一类新的生成模型,无需对抗训练即可快速获得高质量样本。与此同时,OpenAI还发布了ConsistencyModels实现以及权重。

论文地址:
代码地址:
具体而言,ConsistencyModels支持快速one-step生成,同时仍然允许few-step采样,以权衡计算量和样本质量。它们还支持零样本(zero-shot)数据编辑,例如图像修复、着色和超分辨率,而无需针对这些任务进行具体训练。ConsistencyModels可以用蒸馏预训练扩散模型的方式进行训练,也可以作为独立的生成模型进行训练。
研究团队通过实验证明ConsistencyModels在one-step和few-step生成中优于现有的扩散模型蒸馏方法。例如,在one-step生成方面,ConsistencyModels在CIFAR-10上实现了新的,在ImageNet64x64上为6.20。当作为独立生成模型进行训练时,ConsistencyModels在CIFAR-10、ImageNet64x64和LSUN256x256等标准基准上的表现也优于single-step、非对抗生成模型。
有网友将其视为扩散模型的有力竞争者!并表示ConsistencyModels无需对抗性训练,这使得它们更容易训练,不容易出现模式崩溃。
还有网友认为扩散模型的时代即将结束。
更有网友测试了生成速度,3.5秒生成了64张分辨率256×256的图片,平均一秒生成18张。
接下来我们看看ConsistencyModel零样本图像编辑能力:
图6a展示了ConsistencyModel可以在测试时对灰度卧室图像进行着色,即使它从未接受过着色任务的训练,可以看出,ConsistencyModel的着色效果非常自然,很逼真;图6b展示了ConsistencyModel可以从低分辨率输入生成高分辨率图像,ConsistencyModel将32x32分辨率图像转成256x256高分辨率图像,和真值图像(最右边)看起来没什么区别。图6c证明了ConsistencyModel可以根据人类要求生成图像(生成了有床和柜子的卧室)。
ConsistencyModel图像修复功能:左边是经过掩码的图像,中间是ConsistencyModel修复的图像,最右边是参考图像:
ConsistencyModel生成高分辨率图像:左侧为分辨率32x32的下采样图像、中间为ConsistencyModel生成的256x256图像,右边为分辨率为256x256的真值图像。相比于初始图像,ConsistencyModel生成的图像更清晰。
模型介绍
ConsistencyModels作为一种生成模型,核心设计思想是支持single-step生成,同时仍然允许迭代生成,支持零样本(zero-shot)数据编辑,权衡了样本质量与计算量。
我们来看一下ConsistencyModels的定义、参数化和采样。
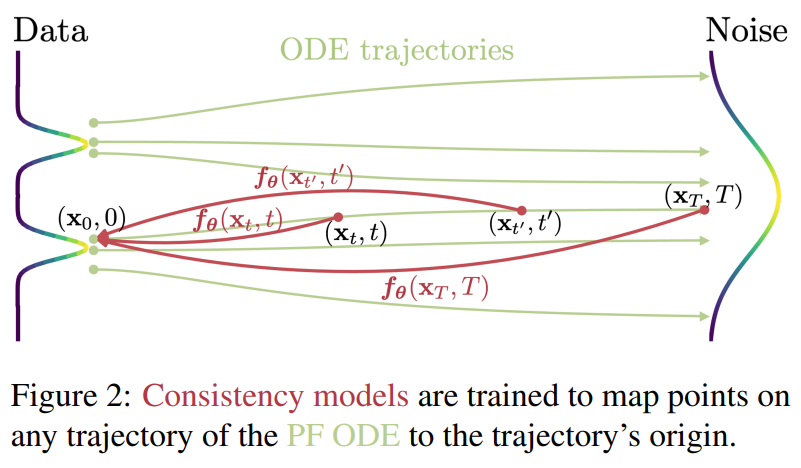
首先ConsistencyModels建立在连续时间扩散模型中的概率流(PF)常微分方程(ODE)之上。如下图1所示,给定一个将数据平滑地转换为噪声的PFODE,ConsistencyModels学会在任何时间步(timestep)将任意点映射成轨迹的初始点以进行生成式建模。ConsistencyModels一个显著的特性是自洽性(self-consistency):同一轨迹上的点会映射到相同的初始点。这也是模型被命名为ConsistencyModels(一致性模型)的原因。
ConsistencyModels允许通过仅使用onenetwork评估转换随机噪声向量(ODE轨迹的端点,例如图1中的x_T)来生成数据样本(ODE轨迹的初始点,例如图1中的x_0)。更重要的是,通过在多个时间步链接ConsistencyModels模型的输出,该方法可以提高样本质量,并以更多计算为代价执行零样本数据编辑,类似于扩散模型的迭代优化。
在训练方面,研究团队为ConsistencyModels提供了两种基于自洽性的方法。第一种方法依赖于使用数值ODE求解器和预训练扩散模型来生成PFODE轨迹上的相邻点对。通过最小化这些点对的模型输出之间的差异,该研究有效地将扩散模型蒸馏为ConsistencyModels,从而允许通过onenetwork评估生成高质量样本。
第二种方法则是完全消除了对预训练扩散模型的依赖,可独立训练ConsistencyModels。这种方法将ConsistencyModels定位为一类独立的生成模型。
值得注意的是,这两种训练方法都不需要对抗训练,并且都允许ConsistencyModels灵活采用神经网络架构。
实验及结果
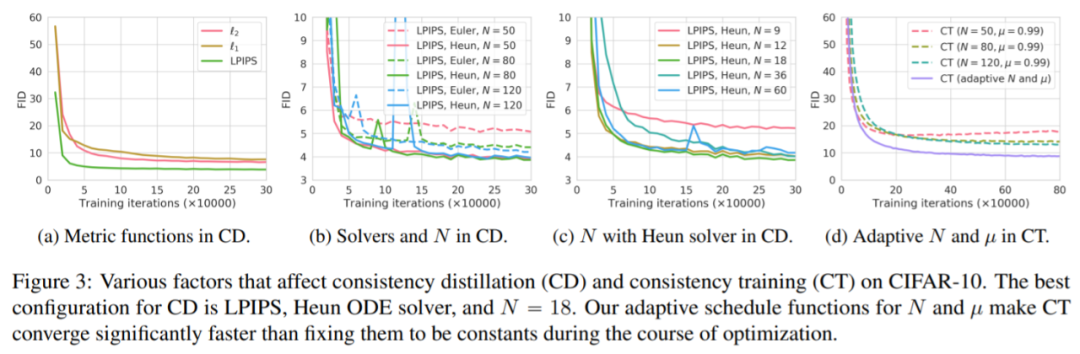
实验数据集包括CIFAR-10、ImageNet64x64、LSUNBedroom256x256、LSUNCat256x256。首先该研究在CIFAR-10上进行了一系列实验。结果图3所示。
Few-Step图像生成
接着该研究在ImageNet64x64、LSUNBedroom256x256数据集上进行实验,结果如图4所示。
表1表明,CD(consistencydistillation)优于KnowledgeDistillation、DFNO等方法。
表1和表2表明CT(consistencytraining)在CIFAR-10上的表现优于所有single-step、非对抗性生成模型,即VAE和归一化流。此外,CT在不依赖蒸馏的情况下获得与PD(progressivedistillation)相当的质量,用于single-step生成。
了解更多内容,请参考原论文。